Affinity
You have some nested loop and you found a strategy to parallelize it. You don’t introduce false sharing, race conditions, anything you don’t want. It looks somewhat like this when using OpenMP:
# pragma omp parallel for // collapse, ...
for (size_t i = 0; i < nx; i += kx)
// do work
Do you let your OS or your OpenMP implementation decide where these threads are sitting?
Luckily, there are several tools that can help you explore these choices.
An example: I’m running on some Ryzen chip. lstopo is a nice command giving you some insight into
how you can allocate your resources.
It looks like this on my side:
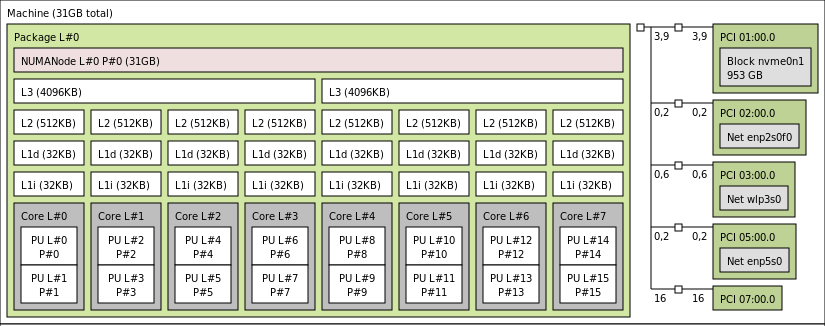
As we can see there are 8 physical cores available to me.
Setting the affinity to a thread is now done with
GOMP_CPU_AFFINITY="0,2,4,6,8,10,12,14"
Why did I do it like this here? My specific loop makes use of independent data for every thread. You don’t want threads sitting on the same island to hammer your bus as this will reduce performance. There are possibly applications where using
GOMP_CPU_AFFINITY="0,1,2,3,4,5,6,7"
is practical – you will have to benchmark this for your specific case. Notably, $GOMP_CPU_AFFINITY will not set the number of threads used per se.
Having understood this setup, it’s easy (RTFM) to distribute this work onto several nodes if you’ve got MPI enabled. You’d want to rewrite this as a loop when on a cluster.
mpirun -np 1 -x OMP_NUM_THREADS=4 -x GOMP_CPU_AFFINITY="0,2,4,6" ./to_mpi $1 \
: -np 1 -x OMP_NUM_THREADS=4 -x GOMP_CPU_AFFINITY="8,10,12,14" ./to_mpi $1
If I’ve done my homework and haven’t left any single-core and OpenMP performance on the table, this should come close to what’s possible on my machine. Of course, you now have to watch out for communication overhead and load imbalance. Maybe I’ll explore this at a later point.